- Published on
Building a Responsible AI Solution - Principles into Practice
- Authors

- Name
- Humayoun Kabir Emon
- @hkemon007
Table of Contents
Introduction
This is part 2 of my series of posts on fairness in AI, reflections from a participant in the Monetary Authority of Singapore's (MAS) Global Veritas Challenge. In my first post, I discussed the need to adopt a human-centric approach when dealing with issues of fairness in AI systems. After hours of brainstorming, user interviews and smashing bits of code together, we created VerifyML, an open-source framework to help organisations build fair and responsible models. The solution was one of the three winning submissions of the Veritas challenge!
4 minutes VerifyML pitch
My teammates have written about VerifyML in detail, so if you are interested in giving it a spin, check out the following introductory posts:
- Introducing VerifyML
- A Quickstart Guide to VerifyML Part 1
- A Quickstart Guide to VerifyML Part 2
- Comparing VerifyML, AI Fairness 360 and Fairlearn
In this post, I take a step back and share some of the things I have learned while developing this solution. I start from the user interviews and feedback that we have gathered, before discussing existing tools in the model governance space, and concluding with how we designed a solution that addresses the problem.
User interviews and feedback

The competition gave us many opportunities to engage with a variety of stakeholders who were involved in trying to implement responsible AI workflows in their organisations.1 While the organisations all have slightly different workflows, there were three recurring pain points that caught our attention:
- Friction in exchange of information between teams
- Difficulty in synchronizing data science code with docs
- Difficulty aligning code with regulatory requirements
Friction in exchange of information between teams
Recognising that the problem is not only one faced by data scientists, but a multi-stakeholder problem that involves product owners, data teams, compliance teams and system engineers shaped our thinking and approach to the problem. Responsible AI is a process, not an outcome, and our solution should be the medium that enables the process to be conducted more efficiently and effectively. The solution also must be the common interface that allows different parties to weigh in throughout the process.
Difficulty in synchronizing data science code with docs
This has always been a nagging problem in our consultation projects so it does not come as a surprise that many data scientists also face challenges synchronizing their code with their documentation. In most projects, documentation is often seen as the least glamorous part of the job and is done only after the project is completed. It is usually hastily written in Microsoft Word and stored in Sharepoint or some internal knowledge base.
This leads to two problems:
- The documentation does not capture the process of building the model and subsequent changes.
- Documentation is not easily discoverable, searchable or editable by others in the team.
Difficulty aligning code with regulatory requirements
This might be more relevant to the competition that we are participating in, but in sectors where machine learning and AI models will be regulated, it is often quite a stretch to align the process which the model is developed with the regulatory requirements which often comes in a form of a multiple questionnaire checklist.
Data scientists do not have the bandwidth or do not think they should be burdened with trying to align their models with regulatory requirements. They also do not know what metrics that they should be using for a given business problem resulting in either a "spray and pray" approach or simply just omitting such fairness analysis.
Meanwhile, accessors / auditors may not have the technical capabilities to understand all the harms and benefits associated with the model.
Tools and solutions in the model governance space

Having teased out the pain points from our users, we wanted to understand more about the lay of the land and what existing tools and solutions are available. The worse possible outcome of the competition would be to spend a month re-inventing the wheel and creating an inferior version of what is out there in the market. We also did not want our solution to be a compliance exercise where the whole thing becomes just a checklist resulting in teams trying to game the system and subvert the process.
With this in mind, we began our explorations in the model governance space. I use the term here quite liberally to refer to the whole suite of solutions meant to help build and deploy machine learning models into production.
The model governance space could be categorized into the following three areas:2
- Model building and experimentation
- Model versioning, deployment and release
- Monitoring and quality control
Here's a brief overview of the three areas. Model building and experimentation tools normally include a large library of algorithms which a data scientist or analyst could easily create machine learning pipelines. It includes popular open-source tools like scikit-learn, as well as commercial solutions like Data Robot and h2o which might have data connectors to existing data marts or databases.
To push a model into production, there are additional concerns which the tools in the versioning, deployment and release space aim to solve. This includes obtaining adequate infrastructure to run the model reliably and facilitating easy model release or rollback. Solutions in the MLOps space includes Kubeflow, Pachyderm and Algorithmia.
While tools in the model experimentation space normally include diagnostic charts on a model's performance, there are also specialised solutions that help ensure that the deployed model continues to perform as they are expected to. This includes the likes of seldon-core, why-labs and fiddler.ai.
This categorisation is relatively simplistic and there certainly are numerous solutions that overlap in capabilities and are positioning themselves as end-to-end machine learning platforms.3
The problem space that we are dealing with involves machine learning issues but also compliance and operation processes. Some of the existing solutions support responsible AI development by providing model explainability and fairness analysis, but these explainability or fairness reports tend to be consumed by technical experts i.e. the data scientist. There seems to be a gap for solutions to cater to less technical stakeholders, including internal management teams as well as customers.4
Existing solutions in the monitoring and quality control space also served as a great source of inspiration in developing a model governance solution. There are some attempts at placing a regulatory layer on top of these systems, but it strikes me as an odd fit simply because these existing solutions do not cater to non-technical users. Nonetheless, the idea of monitoring the results of a machine learning model in production and providing reports on performance drift or degradation in other aspects of a model is something we adapted as part of our solution.
Designing VerifyML
Having bashed our way around the model governance ecosystem, we needed to distil our knowledge to a minimum viable product. When designing a solution for a competition, especially against other competitors with existing products, I find it very helpful to identify a niche to position ourselves. Essentially, we want it to be a competition of ideas rather than who has the best technical implementation. It's also mandatory to have a visual prototype so that the ideas can be easily communicated and understood.5
We decided to carve a niche around model documentation and testing. While tools to build and deploy AI/ML models have flourished and grown, the area of documentation and testing has been mostly neglected. If we could create a solution to improve the documentation and testing process, one that includes the needs and requirements of other stakeholders, we think that it would be a nice complement to the existing model governance ecosystem.
Model documentation
Better documentation is a relatively easily sell - it's something everyone does not really like to do but is required to do. As mentioned previously, teams currently document their findings through various word documents, PowerPoint slides, README.md files or (gulp) Jupyter Notebook.
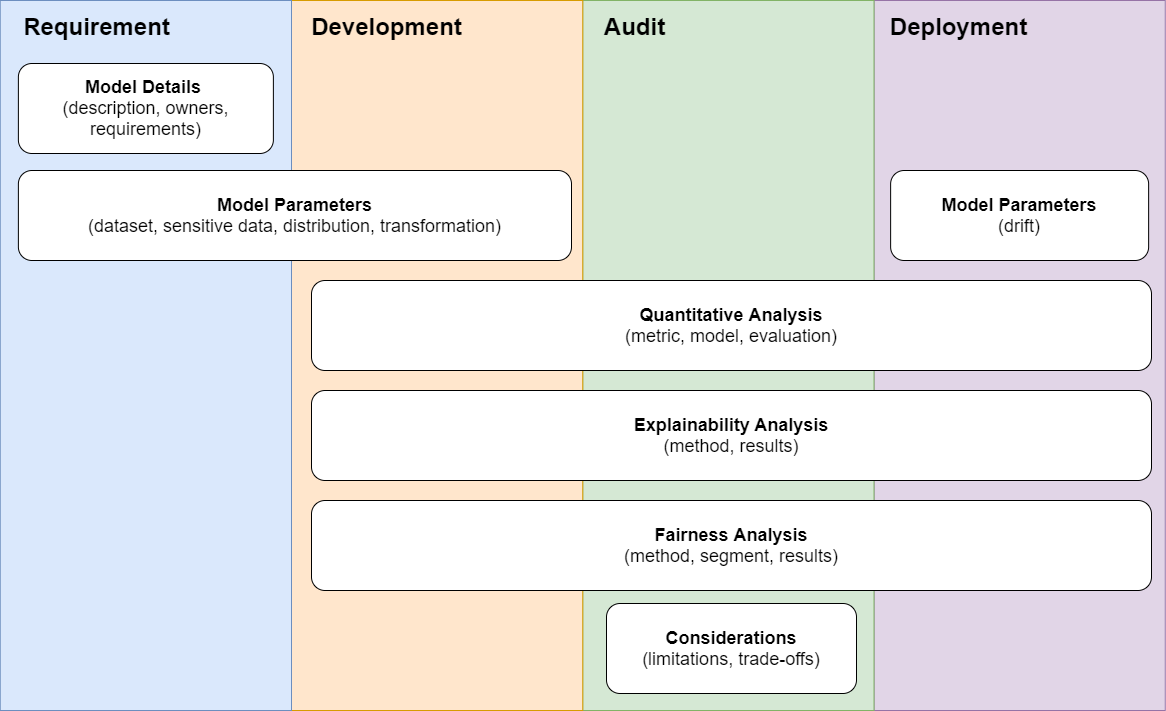
The diagram above maps out the key phases of a machine learning development lifecycle, along with the various pieces of information that should be extracted from the phases and inserted in a model's documentation.
With VerifyML, we are creating a more structured approach to documentation, one that aligns with the requirements of various stakeholders - product owners, developers and compliance. Documentation is done automatically in a way that the production model and the docs are always in sync. By integrating documentation in a data science workflow, we can automate the creation of boilerplate reports, improve integration with existing tools and make it a collaborative process (rather than a chore).
We explored various solutions in the machine learning space as well as in the neighbouring software development space for inspiration and learning. Some notable ones include Git and Github, Google Model Cards (Mitchell et al., 2019) and IBM's Factsheets (Arnold et al., 2019).^[Here's an example of a face detection model card created as part of Google Cloud's Cloud Vision API. The model card created using the open-source library is relatively much simpler and less interactive. After the competition, I was also informed of DAG Card, another model card spin-off that integrates with Metaflow to create a self-documenting ML pipeline from code and comments. Here's an example of a mortgage model evaluation factsheet, which is supposedly integrated with IBM Watson's product.] One of the main design decisions we faced was whether to go with a plain-text git-based solution or a structured schema approach. Eventually, we decided to build on top of Google Model Card (structured protobuf schema). This sacrifices immediate readability of the file, but makes it easy to be processed across different systems in a predictable manner.
Model testing
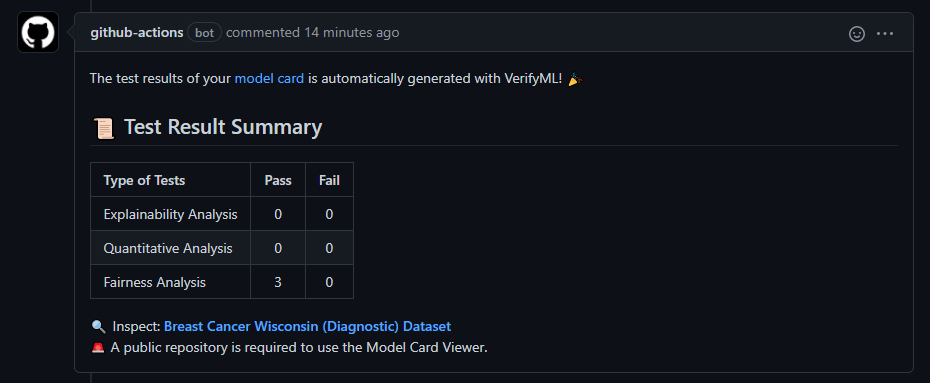
Model testing is a relatively foreign concept - software development best practices have not really trickled down to applied machine learning. Testing exists mostly at the framework or algorithm developing stage, but not when it comes to developing models on top of these algorithms. To some extent, a train / test split could be regarded as a test, that of robustness to overfitting, but running it as part of a Jupyter Notebook obscures the intent and makes it hard to replicate.
Our goal over here is to make these test cases more explicit and promote them to first class data objects that should be maintained, just like test suites in a source code. In engineering speak, model tests are system tests or acceptance tests that ensure that the model meets (and continues to meets) certain prescribed specification. For an AI/ML model, this would include measures of model performance as well as additional considerations like robustness and fairness.
Besides the existing monitoring solution mentioned in the section above, we were also took inspiration from continuous integration and continuous delivery (CI/CD) testing tools like Jenkins and Circle CI, on the engineering front, and existing fairness libraries like Microsoft's Fairlearn (Bird et al., 2020) and IMB's Fairness 360 (Bellamy et al., 2019), on the machine learning side of things.
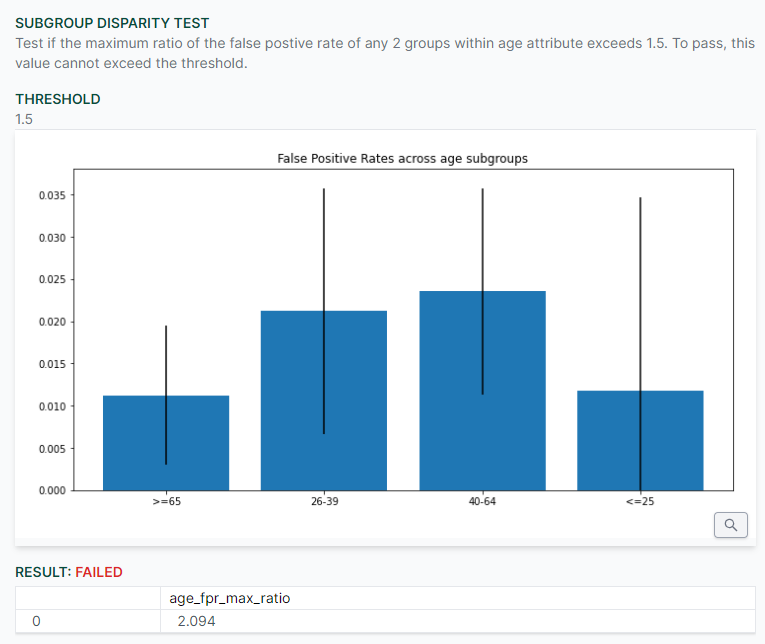
We decided to create a Python library that provides out of the box test methods for common data science use cases. As a proof of concept, we built the library around binary classification problems.6 Developing on top of a scikit-learn API proved to be relatively simple and allows us to support most of the existing machine learning Python frameworks.7 We then focused our efforts on re-framing and re-categorizing the available methods in the fairness literature. Rather than provide more than twenty different metrics which either map to similar concepts or are simply incompatible from a theoretical sense (see Barocas et al., 2019), we let users specify the base metrics that they are interested in comparing and specify an acceptable threshold of deviation.8
VerifyML architecture and solution overview
In creating the solution, we felt that the synergies of having documentation and testing in a single solution outweighed the complexity of having to develop both parts. Namely, we would be able to create a solution where test results can be synchronized with the documentation, which acts as a source of truth on all details related to the model. This means that docs are not just static reports to be filled at the end of a model building process, but are evolving documentation that iterates through the conception, development and eventual production of the model.
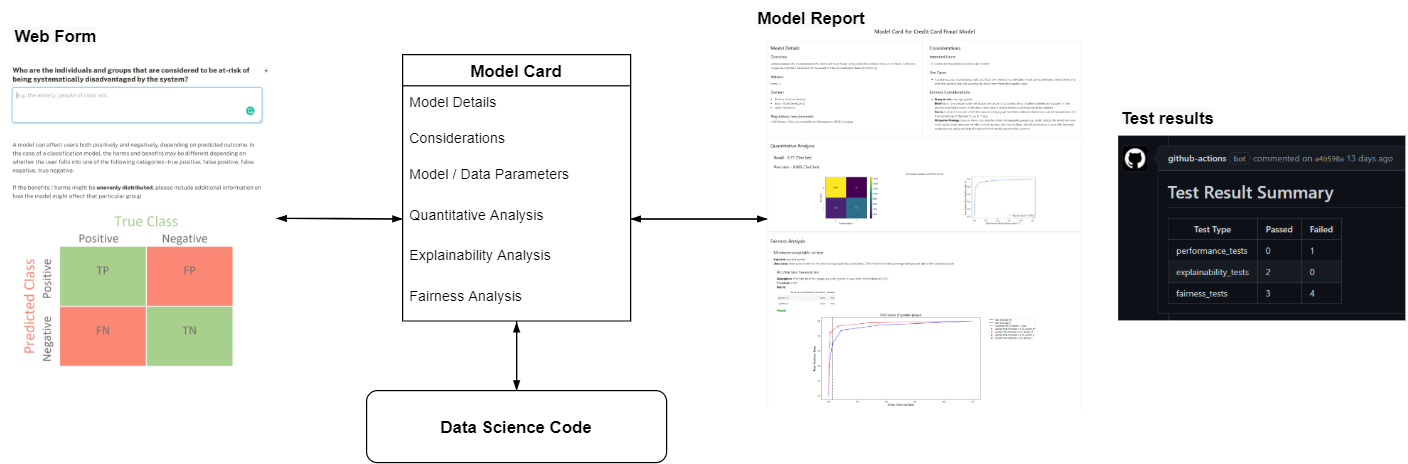
The above diagram outlines the data flow of our framework. Every model that is created is accompanied by a model card. This acts as the a source of truth, where teams can document qualitative and quantiative aspects of the model, including business objectives, performance analysis and fairness considerations. Teams would be able to iterate on the card from the initial project conception to eventual deployment.
The model card can be easily edited by both business as well as technical users, either through a web form interface or through the Python library. For example, a product owner could fill up the section on the model's objectives through the web form, while a data scientist would update the section on model explainability with the help of the Python library.
The VerifyML python library also makes it easy to test an existing scikit-learn compatible model and ensure that the current model meets certain standards. Naturally, the test results can also be easily appended to the documentation to complete the cycle.

We extend Google Model Card by not only supporting the creation of html reports from the python library, but also creating a separate web app for teams to view the results.9 There's also a comparison view that allows easy comparison between different model runs or model deployments. Since the competition, we have also created a Github Action which automatically parses the model card in every pull request and checks that the model passes all the required test cases.
Conclusion
Are any of the ideas truly original? I doubt so, but I think we did a good job stitching together various components and making it easy for any company to improve their model documentation and testing processes. Our holistic approach to the problem and the fact that it solves common pain points in the model development lifecycle probably won the votes from the judging panel.
Interested readers should check out the VerifyML website, docs or Github code. Feel free to create a Github issue and drop any suggestions or feedback over there! VerifyML is proudly open-sourced and created by a small tech startup. I would like to think that more companies are going to see responsible AI as a comparative advantage or requirement and having an ecosystem of solutions that are not controlled by the interests of large tech companies would be key in driving the sector forward. I look forward to improving the user experience and integration with more machine learning tools over the next year, as well as sharing more thoughts in the space.
References
Footnotes
I thank the teams from UOB, BNY Mellon, Standard Chartered, Google and MAS for their sharing. ↩
One could further subdivide it by the different types of model e.g. image recognition vs NLP but we will omit these details for the analysis. ↩
From my brief experience trying out some of these solutions, I do think they tend to excel in a particular area while being satisfactory in others. The main difficulty with a full end-to-end platform is that it forces the organization to totally buy into the solution, and using external tools or minor deviations in work processes becomes a huge undertaking. ↩
I think it would be really cool if consumers can get a report to find out why they were accepted or rejected by a machine learning model and how they could potentially change that outcome. This would be the algorithmic counterpart of GDPR and would give consumers certain rights when their information is being processed by AI/ML systems. ↩
Here's a competition tip - most of the evaluation happens through the pitch and judges would not have time to review the submitted materials (or execute code), so it is of utmost importance to prepare the story that you plan to deliver ahead of time. Selling the idea and vision matters more than technical perfection. ↩
We have since expanded support to both binary classification and regression problems. ↩
We do not actually require a scikit-learn class, only that it contains a train and fit function. ↩
For example, instead of having a new "equality of opportunity" measure, this would simply be equal false-negative rate, and instead of having a new "equalized odds" measure, we can simply call it equal false-negative and false-positive rate, improving clarity and reducing jargon. ↩
Currently, editing is done through a separate web form, but we plan to integrate them into a single solution in the near future. ↩